2. 데이터 모델과 성능#
1. 성능 데이터 모델링#
DB 성능향상을 위한 사항이 데이터 모델링에 반영되도록 하는 것
수행 시점 : 분석/설계 단계, 성능 데이터 모델링 시점이 늦어질수록 재업무 비용이 증가함.
고려 사항 : 정규화 수행, DB 용량 산정과 트랜잭션 유형 파악을 통한 반정규화 수행, 정규하는 무조건 해야함.
2. 정규화 Normalization#
정규화란 다양한 분야에서 사용되는 개념으로, 주로 데이터나 값의 범위를 일정하게 조정하여 분석이나 처리를 더 효율적으로 할 수 있도록 하는 과정을 말한다. 주로 데이터베이스, 통계학, 머신러닝, 인공지능에서 활용된다. 정규형 Normal Form(NF) 정규화로 도출된 데이터 모델이 갖춰야할 특성
즉 정규화는 데이터 모델이 정규성을 가지도록 하는 과정을 말하는 것. 높은 단계의 정규형은 그 이전의 정규형들이 갖는 조건들을 만족해야한다. 핵심 정규형은 BCNF, 5NF이며, 그외의 정규형을 목표로 하지 않는다.
정규화의 목적#
데이터 일반화 : 데이터를 일정한 범위 내로 조정함으로써 데이터가 서로 다른 단위나 크기를 가지더라도 비교가 가능하게 한다.
이상치 제거 : 데이터에 이상치(극단적인 값)가 포함될 경우, 이상치로 인한 왜곡을 줄여 정확한 분석을 돕는다.
성능 개선 : 머신러닝 모델이나 통계적 분석에서 데이터의 범위가 작을 경우 모델이 더 빠르게 수렴하거나 성능이 향상될 수 있다.
계산 효율성 : 정규화된 데이터는 연산이 더 간단하며 효율적으로 수행될 수 있다.
정규화의 방법#
최소최대 정규화(MinMax) : 값을 0~1 사의의 범위로 조정. 1)각 값에 대해 최소값을 빼고 2)(최대값-최소값)으로 나누어 계산
Z-점수 정규화(Z-Score) : 데이터를 평균이 0이고 표준편차가 1이 되도록 조정. 1)각 값에서 평균을 빼고 2)표준편차로 나누어 계산
벡터 정규화(Vector) : 다차원 데이터에서 각 데이터 벡터의 크가기 동일하도록 정규화. 이를 통해 거리 기반 알고리즘에서 데이터 간 거리 계산이 공정하게 이루어진다.
로그 변환(Log) : 데이터가 넓은 범위를 가지는 경우, 로그 변환을 통해 데이터 분포를 조정하여 모델 성능을 향상시키는 경우가 있음.
함수적 종속성 Functional Dependency#
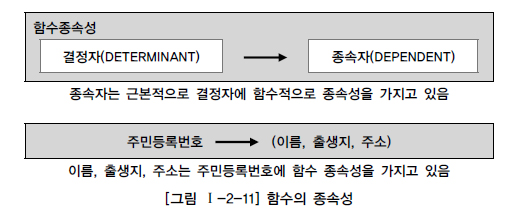
결정자와 종속자의 관계
결정자의 값으로 종속자의 값을 알 수 있음
어떤 관계의 속성 a,b가 있다고 가정할 때, a의 값을 알면 b의 값을 알 수 있는 관계를 말한다. 이때 a 값은 유일해야하며, b는 중복되어도 상관 없다. 즉, 키의 값을 알면 다른 임의의 속성 값을 구할 수 있는 것 처럼 키의 성질을 정의한 것이라고 할 수 있다. 다치 종속(Multivalued Dependency) 여러 컬럼이 동일한 종속자 일때
사람이라는 엔터티는 주민등록번호, 이름, 출생지, 호주라는 속성이 존재한다. 여기에서 이름, 출생지, 호주라는 속성은 주민등록번호 속성에 종속된다. 만약 어떤 사람의 주민등록번호가 신고되면 그 사람의 이름, 출생지, 호주가 생성되어 단지 하나의 값만 가지게 된다. 이를 기호로 표시하면 다음과 같이 표현할 수 있다.
주민등록번호 -> (이름, 출생지, 호주)
이를 다시 표현하면 ‘주민등록번호가 이름, 출생지, 호주를 함수적으로 결정한다’라고 말할 수 있다. 실세계의 데이터들은 대부분 이런 함수적 종속성을 가지고 있다. 함수의 종속성은 데이터가 가지고 있는 근본적인 속성으로 인식된다. 정규화의 궁극적인 목적은 반복적인 데이터를 분리하고 각 데이터가 종속된 테이블에 적절하게 배치되도록 하는 것이므로 이 함수의 종석석을 이용하여 정규화 작업이나 각 오브젝트에 속성을 배치하는 작업에 이용된다.
정규화 이론#
1차 2차 3차 보이스코드 정규화는 함수적 종속성에 근거
4차 정규화는 다치 종속을 제거. 결합 종속성 제거
5차 정규화는 조인에 의한 이상현상을 제거하여 정규화를 수행함
1차 정규화 : 속성의 원자성 확보, 다중값 속성을 분리함
1차 정규형 1NF
“릴레이션이어야 한다.”
테이블에는 컬럼이나행에 순서가 존재하지만, 릴레이션에는 순서가 존재하지 않기 떄문에 순서를 고려하지 않는다.
중복되는 튜플이 존재하지 않음
구체적인 값을 가져야한다. 즉 값으로 NULL값을 가지지 않는다.
값은 의미가 있는 한 묶음의 데이터, 즉 원자 단위여야 한다.(원자성)
원자 단위이려면, 각 행마다 한 컬럼에 하나의 값을 가져야 한다.
2차 정규화 : 부분 함수 종속성 제거, 일부 기본키에만 종속된 속성을 분리함. 기본키가 하나의 컬럼일 때 생략 가능
2차 정규형 2NF
부분 함수 종속성
후보키의 진부분집합에서 키가 아닌 속성에 대해, 부분 함수 종속성을 제거하는 작업
릴레이션이 1NF 조건을 만족하고, 부분 함수 종속성을 가지지 않으면 2NF라고 할 수 있다.
3차 정규화 : 이행 함수 종속성 제거, 서로 종속관계가 있는 일반 속성을 분리함, 주 식별자와 관련성이 가장 낮음
이행 함수 종속성
추이 함수 종속성을 제거하는 작업
추이 함수 종속성은 키가 아닌 애트리뷰트 사이의 함수 종속석을 의미한다.
키가 아닌 애트리뷰트 x,y가 있고, x를 알면 y값을 알 수 있는 함수 종속성이 있다고 가정해보자.
3NF는 xy사이의 함수 종속성을 제거하는 과정이다.
2NF는 후보키와 키가 아닌 애트리뷰트 사이의 함수 종속성을 제거했단느 점에서 차이가 있다.
보이스 코드 정규화(BCNF; Boyce-Codd Normal Form) : 후보키가 기본키 속성 중 일부에 함수적 종속일 때 다수의 주식별자를 분리함
키가 아닌 애트리뷰트 사이에서 후보키의 진부분집합에 대한 함수 종속성을 제거하는 작업
BCNF는 함수 종속성이 모두 제거된 상태의 정규형을 말한다.
앞서 2NF와 3NF 그리고 BCNF를 거쳐 모든 경우의 수에 대해 함수 종속성을 제거했기 때문이다.
이로 BCNF이상에서 함수 종속성에 의한 무손실 분해를 할 수 없다.
4차 정규화 : 다치 종속 분리
MVD(multivalued dependency - 다치 종속성) 제거.
폭넓게는 결합 종석성을 제거하는 과정이다
속성 a를 알면 x라는 다중값(bc 속성값)을 알 수 있을 때, 이러한 종속성을 제거하는 것
5차 정규화 : 결합 종속 분리
4차와 마찬가지로 결합 종속성 제거
a,b,c 가 있을때 ab bc ac 속성 조합을 갖는 관계로 분해될 수 있을때, 이러한 결합 종속성을 제거하는 것
6차 정규성도 있지만 6차 정규성까지 하게 되면 관계가 너무 많아지므로 join을 많이 하게 된다는 단점이 존재한다.
정규화와 성능#
정규화는 입출력 데이터의 양을 줄여서 성능을 향상시킴
성능 향상
입력 수정 삭제 시 성능은 항상 향상됨
유연성 증가 : High Cohesion(응집력) & Loose Coupling 원칙에 충실해짐
재활용 가능성 증가 - 개념이 세분화됨
데이터 중복 최소화
성능 저하
조회시 처리 조건에 따라 성능 저하가 발생할 가능성도 존재함
데이터 조회시 조인을 유발하여 CPU와 메모리를 많이 사용하게 됨
반정규화로 해결 가능
조인이 발생하더라도 인덱스를 사용하여 조인 연산을 수행하면 성능 상 단점이 거의 없고, 정규화를 통해 필요한 인덱스의 수를 줄일 수 있음
정규화를 통해 소량의 테이블이 생성되면 성능상 유리할 수 있음
3. 반정규화 Denormalization#
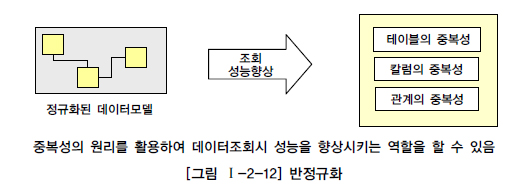
Fig. 20 반정규화란#
데이터 중복을 허용하여 조인을 줄이는 DB 성능 향상 방법
데이터의 무결성을 희생하고 조희 성능을 향상
아예 정규화를 수행하지 않은 모델을 지칭할 때 사용
정규화된 엔티티,속성,관계에 대해 시스템의 성능향상과 개발 운영의 단순화를 위해 중복, 통합, 분리등을 수행하는 데이터 모델링의 기법을 의미
기본적으로 정규화는 입력/수정/삭제에 대한 성능을 향상시킬 뿐만 아니라 조회에 대해서도 성능을 향상시킨다. 그러나 정규화 만을 수행하면 엔터티의 갯수가 증가하고 관계가 많아져서 일부 여러 개의 조인이 걸려야만 데이터를 가져오는 경우가 있다. 이러한 경우 업무적으로 조회에 대한 처리 선응이 중요하다고 판단될 때 부분적으로 반 정규화를 고려하게 되는 것이다. 또한 정규화의 함수적 종속관계는 위반하지 않지만 데이터의 중복성을 증가시켜야만 조회의 성능을 향상시키는 경우가 있다.
프로젝트에서는 설계단계에서부터 반정규화를 적용하게 되는데 반정규화를 기술적으로 수행하지 않으면 성능이 저하된 DB가 생성될 수 있으며, 구축단계나 시험단계에서 반정규화를 적용할 때 수정에 따른 노력비용이 증가한다.
반정규화 절차#
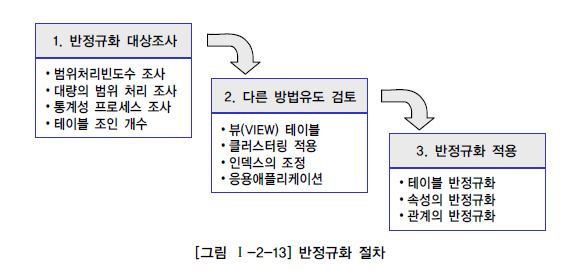
Fig. 21 반정규화 절차#
반정규화 대상 조사 : 데이터 처리 범위 및 통계성 등 조사
전체적인 데이터의 양을 조사하고 데이터가 해당 프로세스를 처리할 때 성능저하가 나타날 수 있는지 검증
아래의 4가지 경우를 고려하여 반정규화를 고려
자주 사용되는 테이블에 접근하는 프로세스의 수가 많고 항상 일정한 범위만을 조회하는 경우
큰 사이즈의 테이블에 대해서 처리범위를 일정하게 줄이지 않으면 성능을 보장할 수 없을 때
통계성 프로세스에 의해 통계 정보를 필요로 할 때 별도의 통계테이블(반정규화 테이블) 생성
테이블에 지나치게 많은 조인이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우
다른 방법 검토
뷰 VIEW
클러스터링 적용
인덱스 조정
파이셔닝 기법 : 인위적인 테이블을 통합 분리하지 않고 물리적인 저장기법에 따라 성능을 향상
응용 어플리케이션
반정규화 적용 : 정규화 수행 후 반정규화 수행
반정규화 기법#
테이블 반정규화
테이블 병합
1:1 관계 테이블 병합
1:N 관계 테이블 병합 : 많은 데이터 중복 발생
슈퍼타입/서브타입 테이블 병합
테이블 분할
수직분할
수평분할
테이블 추가
중복 테이블 : 업무나 서버가 다를 때 중복 테이블 생성(원격조인 제거)
통계 테이블
이력 테이블
부분 테이블 : 자주 이용하는 컬럼으로 구성된 테이블 생성
컬럼 반정규화
중복 컬럼 추가
파생 컬럼 추가 : 필요한 값 미리 계산한 컬럼 추가
이력 테이블 컬럼 추가
PK에 의한 컬럼 추가 : PK의 종속자를 일반속성으로 생성
응용 시스템의 오작동을 위한 컬럼 추가
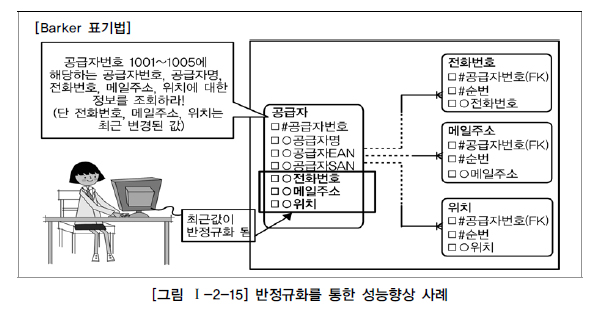
관계 반정규화 : 데이터 무결성 보장 가능
중복 관계 추가
데이터 무결성에 영향을 미치지 않으면서 데이터 처리 성능을 향상시킬 수 있느 기법
데이터 모델 전체가 관계로 연결되어 있고 관계가 서로 먼 친척간에 조인관계가 빈번하게 되어 성능저하가 예상되면
4. 대용량 데이터에 따른 성능#

테이블 반정규화중 테이블 분할 관련
대량의 데이터가 처리되는 테이블에 성능이 저하되는 이유는 SQL문장에서 데이터를 처리하기 위한 I/O의 양이 증가하기 때문이다. 당연하게 데이터의 양이 많아자면 그것을 처리하기 위한 I/O량이 많아질 것이라 생각할 수 있지만, 인덱스를 적절하게 구성하여 이용하게되면 I/O를 줄일 수 있을 것이라고 생각할 수 있다. 조회조건에 따른 인덱스를 적절하게 이용하면 해당 테이블에 데이터가 아무리 많아도 원하는 데이터만 접근하면 되기 때문에 I/O의 양이 그다지 증가하지 않을 것으로 생각할 수 있다.
그러나 대량의 데이터가 하나의 테이블에 존재하게 되면 인덱스를 생성할 때 인덱스의 크기(용량)가 커지게 되고 그렇게 되면 인덱스를 찾아가는 단계가 깊어지게 되어 조회의 성능에도 영향을 미치게 된다. 인덱스 크기가 커질 경우 조회의 성능에는 영향을 미치는 정도가 작지만 데이터를 입력/수정/삭제하는 트랜잭션의 경우 인덱스의 특성상 일량이 증가하여 더 많이 성능의 저하를 유발하게 된다. 또한 데이터에 대한 범위 조회시 더 많은 I/O 유발할 수 있게 되어 성능저하를 유발할 수 있게 된다.
칼럼이 많아지게 되면 물리적인 디스크에 여러 블록에 데이터가 저장되게 된다. 따라서 데이터를 처리할 때 여러 블록에서 데이터를 I/O해야 하는 즉 SQL문장의 성능이 저하될 수 특징을 가지게 된다. 물론, 테이블에 칼럼이 많아지는 현상은 정규화이론인 함수적 종속성에 근거하여 당연히 하나의 테이블에 설계할 수는 있다. 그러나 대량 데이터를 가진 테이블에서 불필요하게 많은 양의 I/O를 유발하여 성능이 저하되는 경우에는 이것을 기술적으로 분석하여 성능을 향상하는 방법으로 분할할 수 있다.
블록 : 테이블의 데이터 저장 단위
대량 데이터 발생으로 인한 현상
블록 I/O(입출력) 횟수 증가
디스크 I/O 가능성 상승(디스크 I/O시 성능 저하)
로우 체이닝(Row Chaining) - 행 길이가 너무 길어 여러 블록에 걸쳐 저장되는 현상
로우 마이그레이션(Row Migration) - 수정된 데이터가 해당 블록이 아닌 다른 블록의 빈 공간에 저장되는 현상
테이블 분할 : 반정규화 기법
수직분할 : 컬럼 단위로 테이블을 분할하여 I/O 감소. 너무 많은 수의 컬럼이 있는 경우 사용
수평분할 : 행 단위로 테이블을 분할하여 I/O 감소.
파티셔닝 Partitioning : 테이블 수평분할 기법
논리적으로는 하나의 테이블이지만 물리적으로 여러 데이터 파일에 분산 저장.
데이터 조회 범위를 줄여 성능 향상
Range Partition : 데이터 값의 범위 기준 분할
List Partition : 특정한 값을 기준으로 분할
Hash Partition : 해시 함수를 적용하여 분할. DBMS가 알아서 분할 관리. 데이터 위치를 알 수 없음
Compose Partition : 여러 파티션 기법을 복합적으로 사용하여 분할
Partition Index 파티션 인덱스
Global Index : 여러 파티션에서 단일 인덱스 사용
Local Index : 파티션 별로 각자 인덱스 사용
Prefixed Index : 파티션키와 인덱스키 동일
Non-Prefixed Index : 파티션 별로 각자 인덱스 사용
5. DB 구조와 성능#
다양한 방식으로 구조를 변환하여 성능을 향상시킴
5-1 슈퍼타입/서브타입 데이터 모델#
슈퍼타입/서브타입 데이터 모델 변환을 통한 성능 향상
속성을 할당하여 배치하는 수평 분할된 형태의 모델
공통 속성은 슈퍼타입으로 모델링하고
차이가 있는 속성은 서브타입으로 구분됨
상속과 유사한 개념으로 생각할 수 있다
변환을 통해 1) 정확하게 업무를 표현할 수 있고 2) 물리적 모델링 시 선택의 폭을 넓힐 수 있음
변환 기준 : 데이터 양, 트랜잭션 유형
변환 기술

1:1 타입(onetoone type) : 개별로 처리하는 트랜잭션에 대해 개별 테이블 구성, 슈퍼타입과 서브타입 각각 필요한 속성과 유형에 적합한 데잍터만 가지도록 분리하여 1:1관계를 가지도록 함
슈퍼/서브 타입(Plus type) : 슈퍼타입과 서브타입을 공통으로 처리하는 트랜잭션에 대해 슈퍼타입과 서브타입 각각의 테이블 구성
All in one 타입(single type) : 일괄 처리하는 트랜잭션에 대해 단일 테이블 구성
1:1타입 |
슈퍼/서브타입 |
All in One 타입 |
|
|---|---|---|---|
특징 |
개별 테이블 유지 |
슈퍼/서브 타입 테이블 구성 |
단일 테이블 구성 |
트랜잭션 유형 |
개별 처리 |
슈퍼/서브 타입 공통 처리 |
일괄처리 |
확장성 |
좋음(테이블 추가 용이) |
보통 |
나쁨 |
조인 성능 |
나쁨(조인 많이 필요) |
나쁨(조인 많이 필요) |
좋음 |
I/O성능 |
좋음 |
좋음 |
나쁨(항상 전체 데이터 조회) |
관리용이성 |
나쁨 |
나쁨 |
좋음 |
표와 같이 각 성능이 좋을 수도 나쁠 수도 있기 때문에 변환모델의 선택은 철저하게 DB에 발생되는 트랜잭션의 유형에 따라 선택해야 한다.
5-2 PK/FK 컬럼 순서 조절을 통한 성능 향상#
등호 조건이나 BETWEEN 조건이 걸리는 컬럼을 앞으로 이동
여러 조건이 있을 경우 등호 조건이 걸리는 컬럼을 선두로 이동
5-3 인덱스 특성을 고려한 PK/FK DB 성능 향상#
물리적인 테이블에 FK 제약을 걸어 인덱스를 생성
6. 분산 DB 데이터에 따른 성능#
분산 DB
분산된 DB를 하나의 가상 시스템으로 사용할 수 있도록 한 DB
물리적 사이트는 분산되어 있으나 논리적으로 동일한 시스템
과거에는 위치 중심이었으나, 현재는 업무 필요에 따라 분산 설계
설계 방식
상향식 : 지역 스키마 작성 후 전역 스키마 작성
하향식 : 전역 스키마 작성 후 지역 사상 스키마 작성
장단점
장점
신뢰성 가용성 증가
빠른 응답 속도와 통신비용 절감
용량 확장 용이
단점
관리 및 통제 어려움
데이터 무결성 관리 어려움
S/W 개발 비용 및 처리 비용 증가
불규칙한 응답 속도
6-1 분산 DB 투명성#
분위지중장병
투명성은 사용자 또는 응용 프로그램이 시스템의 내부 동작과 구조에 대해 자세한 지식 없이 DB 시스템을 사용할 수 있는 정도를 나타낸다. 투명성은 시스템 내부의 복잡한 세부 사항을 알 필요 없이 데이터에 접근하고 조작할 수 있는 능력을 제공한다. 투명성은 분산 시스템의 복잡성을 감추고 사용자 경험을 향상시키는데 도움을 준다.
분할 투명성 : 하나의 논리적 관계가 분할되어 각 단평의 사본이 여러 사이트에 저장됨
위치 투명성 : 사용하려는 데이터 저장 장소가 명시되지 않아도됨
지역사상 투명성 : 지역 DBMS와 물리적 DB 사이에 사상이 보장됨
중복 투명성 : DB 객체 중복 여부를 몰라도됨
장애 투명성 : 구성요소(DBMS, computer)의 장애에 무관하게 트랜잭션의 원자성이 유지됨
병행 투명성 : 다수의 트랜잭션을 동시 수행했을 때 결과의 일관성이 유지됨. 병렬 아님
6-2 분산 DB 적용 기법#
테이블 위치 분산 : 설계된 테이블의 위치를 분산함
테이블 분할 분산(Table Fragmentation) : 테이블을 쪼개서 분산함
수평분할
수직분할
테이블 복제 분산(Table Replication) : 동일한 테이블을 다른 지역이나 서버에서 동시 생성함, 원격지 조인을 내부 조인으로 변경하여 성능 향상
부분복제
광역복제
테이블 요약 분산(Table Summarization)
분석요약 : 사이트 별 요약정보를 본사에서 통합하여 전체 요약정보 산출
통합요약 : 사이트 별 정보를 본사에서 통합하여 전체 요약정보 산출