1. 빅데이터 분석 기획#
참조
DB 특징
정보의 축적 및 전달 측면 : 기계가독성, 검색가능성, 원격조작성
정보 이용 측면 : 정보요구에 따라 신속 획득, 정확하고 경제적으로 검색 가능
정보 관리 측면 : 쳬계적 축적, 새 데이터 추가 갱신 용이
정보기술발전 측면 : 정보처리, 검색-관리 소프트웨어, 관련 하드웨어, 정보 전송을 위한 네트워크 기술등의 발전을 견인할 수 있다.
경제 산업적 측면 : 인프라의 특성을 가지고 있어, 경제 산업 사회 활동의 효율성을 제고하고, 국민의 편의를 증진하는 수단으로써의 의미를 가짐.
빅데이터 특징 - 3V 4V
Volumne 크기 : 대량의 데이터 증가 발생으로 기존 데이터 수집, 관리 한계
Variety 다양성 : 비정형 데이터의 발생으로 다양한 데이터 형식 증가
Velocity 속도 : 실시간 정보 발생으로 데이터의 유입, 처리 속도 요구
Value 가치 : 데이터 전체를 파악하고 패턴을 발견하기가 어렵게 되면서 가치의 중요성 강조
Veracity 정확성 : 빅데이터 기반의 예측 분석 결과에 대한 신뢰성이 중요하게 됨
빅데이터로 인한 변화
사후처리 : 데이터를 사전처리하지 않고, 가능한 많은 데이터를 모으고 다양한 방식으로 조합하여 숨은 인사이트 발굴
전수조사 : IoT Cloud 기술의 발전으로 데이터 처리비용 감소 \(\to\) 전수조사로 변화
질보다 양 : 수집 데이터의 양이 증가할수록 정확도가 높아짐 \(\to\) 양질의 분석 결과 산출에 긍정적 영향
상관관계 : 인과관계 보다는 상관관계를 통해서 특정 현상의 발생 가능성을 포착.
7 빅데이터 기본 테크닉
연관규칙 학습(Association rule learning) : 변인간의 상관관계 찾아내기
유형 분석(Classification tree analysis) : 새로운 데이터의 범주 찾아주기 - segmentation
유전 알고리즘(Genetic algorithm) : 최적화가 필요한 문제의 해결책을 자연 선택, 돌연변이 … 점진적 진화
기계학습(Machine learning)
회귀분석(Regression analysis)
감정분석(Sentiment analysis)
소셜 네트워크 분석(Social network analysis)
데이터 거버넌스
기업에서 사용하는 데이터의 가용성, 유용성, 통합성을 관리하기 위한 정책과 프로세스를 다루며 프라이버시, 보안성, 데이터 품질, 관리규정준수를 강조하는 모델을 말한다.
구성요소 : 원칙, 조직, 프로세스
체계 : 데이터 표준화, 데이터 관리체계, 데이터 저장소 관리, 표준화 활동
분산데이터#
MapReduce - 분산데이터 처리
구글 검색을 위해 개발된 분산환경에서의 병렬 데이터 처리 기법을 말한다. 비공유 구조의 여러노트 pc를 대량으로 병렬처리가 가능하게 하는 기법이다. 모든 데이터는 key-value쌍으로 존재한다.
Map 단계 : GFS 구글파일시스템에서 전달된 청크 단위의 데이터를 key-value 형태의 파일들로 데이터에 기록
Shuffle 단계 : map 단계의 출력 데이터를 키를 기준으로 정렬하고, 동일한 키를 가진 데이터를 같은 reduce 테스크로 전송하는 과정. 동일한 키를 가진 중간 결과들을 같은 reducer로 보내기위한
Sorting and Groupingapple이라는 단어가 여러 문장에서 출현했다면, 모든 apple키와 관련된 값들을 같은 위치로 모아준다.
Reduce 단계 : shuffle 단계를 거친 중간 키와 키의 모든 값들을 받아서 원하는 연산을 수행한다.
HBase - 분산 데이터베이스
HDFS의 칼럼 기반 데이터베이스를 말한다. 구글의 BigTable 논문을 기반으로 개발된 것으로, 실시간 랜덤 조회 및 업데이트 가능하며, 각각의 프로세스들은 개인의 데이터를 비동기적으로 업데이트할 수 있다. 단 MapReduce는 일괄처리 방식으로 수행된다.
분산파일시스템은 분산된 서버에 파일을 저장하고 저장된 데이터를 빠르게 처리할 수 있도록 만든 시스템을 말한다. DB를 분산하여 저정하는 것이다. x86서버의 cpu, ram 등을 사용하므로 장비 증가에 따른 성능향상에 용이하다. 네트워크를 통한 여러 파일을 관리 저장하는 개념이라고 볼 수 있다.
GFS - 구글파일시스템
구글의 대규모 클러스터 서비스 플랫폼의 기반이 되는 파일 시스템. 구성은 client, master, chunk server로 구성된다. chunk는 구글파일시스템에서 파일을 나누는 조각 한 단위 1개를 말하고, 하나의 청크는 64mb의 고정된 크기로 분할되어 저장된다. 마스터는 단일 단위로 파일의 메타 정보를 저장한다. 하트비스 메세지로 청크서버와 연결된다. 청크서버는 청크를 저장하고, 파일을 처리하고, 하트비트 메세지를 마스터에게 전달한다. 클라이언트는 마스터에 청크 인덱스를 요청하고 청크단위로 읽고 쓰기를 하는 주체이다.
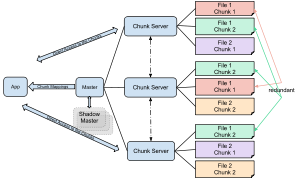
Fig. 33 Google File System is designed for system-to-system interaction, and not for user-to-system interaction. The chunk servers replicate the data automatically.#
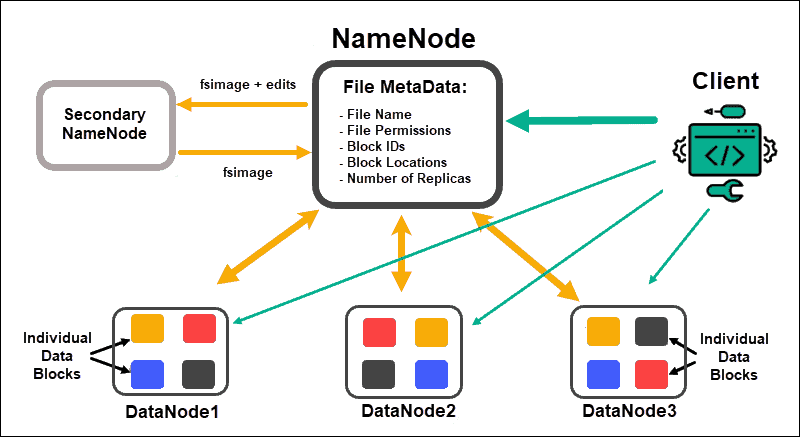
HDFS - 하둡파일시스템
대용량 파일을 분산된 서버에 저장하고, 저장된 데이터를 빠르게 처리할 수 있게하는 하둡 분산 파일 시스템(Hadoop File System)을 말한다. 하둡이 실행되는 파일을 관리해주는 시스템이라고 볼 수 있다. 크게 4가지의 특징이 있다. 기본적으로 스트리밍 방식으로 데이터에 접근하기 때문에 배치 작업과 높은 데이터 처리량에 잘 대응할 수 있다. NameNode에서는 메타데이터를 메모리에서 관리한다. 보조네임노드, 데이터 노드
스트리밍은 네트워크를 통해 오디오,비디오 등의 미디어 데이터를 실시간으로 수집하는 기술을 말한다.
데이터를 복제해서 여러 서버에 저장하며, 복제횟수는 기본적으로 3번이고 복제 횟수를 설정하는 것도 가능하다. GFS와 유사한 소스코드이다.
목적 |
용어 |
특징 |
|---|---|---|
데이터 가공 |
Pig(Pig Latin) |
복잡한 mapreduce 프로그래밍을 대체하기 위해 자체 언어 제공, API 단순화 |
데이터 가공 |
HIVE |
하둡기반 데이터 웨어하우징용 솔루변, Facebook에서 만든 opensource |
데이터 마이닝 |
Mahout |
하둡기반 데이터 마이닝 알고리즘 오픈소스 |
실시간 sql 질의 |
Impala |
HBase연동 하둡 기반 실시간 sql 질의 시스템 |
인메모리 처리 |
Spark |
대용량 처리 위한 인메모리 기반 분산데이터 처리 엔진 |
워크플로우 관리 |
Oozie |
하둡 작업 관리 워크플로우 & 코디네이터 시스템 |
분산 코디네이션 |
Zookeeper |
서버 상호조정 서비스. 하나에 몰리지 않게 해줌 및 동기화하여 데이터 안정성 확보 |
장애복구
스트리밍 방식의 데이터 접근
대용량 데이터 저장
데이터 무결성
개인정보#
개인정보 수집시 동의를 얻지 않아도 되는 경우
사전동의를 받을 수 없는 경우로서 명백히 주체 또는 제 3자의 긴급한 생명, 신체, 재산의 이익을 위하여 필요하다고 인정되는 경우
정보 주체와의 계약의 체결을 위하여 불가피하게 필요한 경우
요금 부과를 위해 회사가 사용자의 정보를 조회하는 경우
법령상 의무를 준수하기 위하여 불가피한 경우
프라이버시모델 추론방지기술
k-익명성 : 일정 확률 수준 이상 비식별조치
l-다양성 : 민감한 정보의 다양성을 높임
t-근접성 : 민감한 정보의 분포를 낮춤
m-유일성 : 재식별 가능성 위험을 낮춤
개인정보 익명 처리 기법
가명 : 개인 식별이 가능한 데이터에 대해 직접 식별할 수 없는 다른 값으로 대체
일반화 : 숫자 데이터의 경우 구간으로 정의하고 범주화된 속성은 트리의 계층적 구조에 의해 대체하는 기법
섭동 : 동일한 확률적 정보를 가지는 변형된 값에 대하여 원래 데이터를 대체하는 기법
치환 : 속성 값을 수정하지 않고 레코드 간에 속성값의 위치를 바꾸는 기법
개인정보차등보호 : 개인정보에 노이즈를 추가해서 개인정보보호와 데이터분석을 모두 진행할 수 있다.
비식별화
데이터 비식별화는 특정 개인을 식별할 수 없도록 개인정보의 일부 또는 전부를 변환하는 방법 데이터를 안전하게 활용하기 위해서는 수집된 데이터의 개인정보 일부 또는 전부를 삭제하거나, 다른 정보로 대체함으로써, 다른 정보와 결합하여도 특정 개인을 식별하기 어렵게 해야한다.
가명처리 : 변경
총계처리 : 총합값으로 처리
데이터삭제 : 중요값 삭제
범주화 : 범주값으로 변경
마스킹 : 대체값
데이터 수집 및 저장 계획#
ETL : 데이터 수집 - 분석을 위한 데이터를 저장소인 DW,DM으로 이동시키기 위해 다양한 소스 시스템으로부터 필요한 원본 데이터를 추출하고 변환하여 적재하는 작업 및 기술
FTP
TCM/IP 프로토콜을 기반으로 서버-클라이언트 상에서 파일 송수신을 하기 위한 프로토콜을 말한다.
Active FTP : 클라이언트가 데이터를 수신받을 포트를 서버에 알려주면, 서버가 자신의 20번 포트를 통해 클라이언트의 임의의 포트로 데이터를 전송해주는 방식
Passive FTP : 서버가 데이터를 송수신해줄 임의의 포트를 클라이언트에 알려주면 클라이언트가 서버의 임의의 포트로 접속해서 데이터를 가져가는 방식